Deep Reinforcement Learning from Human Preferences
This paper shows you can train RL agents using human preferences instead of hand-designed reward functions. Show a human two short clips of agent behavior, ask which is better, and use those comparisons to learn a reward function. This works on MuJoCo robotics tasks (700 comparisons) and Atari games (5,500 comparisons), requiring feedback on less than 1% of the agent's interactions. It can even teach novel behaviors like backflips — in about an hour of human time. Published in 2017 by researchers from OpenAI and DeepMind, this is the foundational RLHF paper whose approach later powered InstructGPT and ChatGPT.
Visualizations (10)
Abstract
- If an RL system needs to be useful, we need to communicate complex goals to these systems.
- In this paper, goals are defined in terms of human preferences between pairs of trajectory segments.
- Therefore, without access to the reward function, the RL task can be solved.
- This works on Atari games and simulated robot locomotion, while providing feedback on less than 1% of the agent's interactions with the environment.
- Novel complex behaviors can be trained with about an hour of human time — considerably more complex than any previously learned from human feedback.
Introduction
- At the time, success was there in scaling RL with well defined reward functions.
- That is not the usual case.
- You can try coming up with a simple function, however, the RL will end up satisfying that function and not solving the overall task.
- For example, suppose you wanted a robot to clean a table or scramble an egg — it's not clear how to write a reward function over the robot's sensors. A simple approximation will often result in behavior that games the reward without actually satisfying your preferences. This is a core concern in AI alignment.
- It'd be better to try to convey objectives to the agents.
- If you have demonstrations of the task, you can extract a reward function by using inverse RL.
- You can use Imitation Learning, to clone the demonstrated behaviour as well.
- Another alternative is to allow a human to provide feedback on the system's current behaviour and use this feedback to define the task, however this is expensive. For deep RL systems, you need a lot of human feedback.
What the paper tries to do is — learn a reward function from human feedback and then optimize that reward function.
- Therefore, we want a well-specified reward function that:
- enables us to solve tasks for which we can only recognize the desired behaviour, but not necessarily demonstrate it
- allows agents to be taught by non-expert users
- scales to large problems
- is economic with user feedback
- The algorithm does two things at once:
- Fits a reward function to the human's preferences
- Simultaneously training a policy to optimize the current predicted reward function
- The paper experiments with two domains — Atari games and robotics tasks in MuJoCo.
- We look for — small amount of feedback, leading to good results.
- Then we see if the algorithm can learn novel behaviours.
Related Work
- Lot of work with RL from human ratings/rankings.
- Some use preferences instead of absolute reward values.
- Old work considers continuous domains with four degrees of freedom and small discrete domains. This work considers physics tasks that have dozens of degrees of freedom & Atari tasks have no hand engineered features.
- Old work with feedback was to have a target policy and fit the reward function to that using Bayesian inference. Synthetic human feedback was drawn from the Bayesian model and used, instead of RL.
#2 RL vs RLHF Pipeline
ManimSide-by-side comparison of the traditional RL pipeline (hand-designed reward) vs the RLHF pipeline (learned reward from human preferences).
Preliminaries and Method
Setting and Goal
- There is an agent interacting with an environment over a sequence of steps; at each time $t$, the agent receives an observation $o_t \in O$ from the environment, and then sends an action $a_t \in A$ to the environment.
- In traditional RL, the environment would give a reward and the agent would like to maximize the discounted sum of rewards.
- However, instead of assuming that the environment produces a reward signal, we assume that there is a human overseer who can express preferences between trajectory segments.
- A trajectory segment — sequence of observations and actions: $$\sigma = ((o_0,a_0), (o_1,a_1),...,(o_{k-1},a_{k-1})) \in (O \times A)^k$$
- Human preferred trajectory segment: $\sigma^1 \succ \sigma^2$
- The goal of the agent, is to produce trajectories that are preferred by human, while making as few queries to the human.
We say that preferences $\succ$ are generated by a reward function $r : \mathcal{O} \times \mathcal{A} \rightarrow \mathbb{R}$ if
This means that preferences imply a higher total reward overall. If we know the reward function $r$, we can evaluate the agent quantitatively. However, sometimes there is no reward function by which we can quantitatively evaluate the same.
Our Method
At each point in time, our method maintains a:
- Policy $\pi : \mathcal{O} \rightarrow \mathcal{A}$
- Reward Function Estimate $\widehat{r} : \mathcal{O} \times \mathcal{A} \rightarrow \mathbb{R}$
Both of which are parametrized by deep neural networks.
These networks are updated by 3 processes:
- Policy $\pi$ interacts with the environment to produce a set of trajectories $\{\tau^1,...,\tau^i\}$. The parameters of $\pi$ are updated by a traditional RL algorithm, in order to maximize the sum of predicted rewards $r_t = \widehat{r}(o_t,a_t)$.
- We select pairs of segments $(\sigma^1, \sigma^2)$ from the trajectories produced in step 1, and then send them to a human for comparison.
- The parameters of the mapping $\widehat{r}$ are optimized via supervised learning to fit the comparisons collected from the human so far.
These 3 processes run asynchronously. Trajectories flow from process 1 → 2, human comparisons from 2 → 3, and parameters for $\widehat{r}$ from 3 → 1.
- Process 1 → Does the stuff and tries things out.
- Process 2 → See's what stuff is done and asks a human to see what was good and what wasn't good.
- Process 3 → Update the rewards based on what the human said.
#1 System Architecture
ManimStep-by-step animation of the three asynchronous processes: policy training, human preference collection, and reward model learning (Figure 1 from the paper).
Optimizing the Policy
After using $\widehat{r}$ to compute the rewards, it becomes a normal RL problem.
We can use any algorithm to solve the problem. However, if $\widehat{r}$ is non-stationary, we would like to choose methods that are robust to changes in the reward function. This is why policy gradient methods are useful.
For this paper:
- Advantage Actor-Critic (A2C) → Atari
- Trust Region Policy Optimization (TRPO) → Simulated Robotics Tasks
Parameter settings were reused from traditional RL tasks. Only entropy bonus was adjusted for TRPO because TRPO relies on the trust region to ensure adequate exploration. If the reward function is changing, there might be inadequate exploration.
Rewards produced by $\widehat{r}$ were normalized to have zero mean and constant standard deviation. This is preprocessing, since the position of the rewards haven't been determined yet.
Preference Elicitation
The human is given a visualization of two segments, in the form of short movie clips, around 1-2 seconds long. The human says which is good, both good, or unable to compare.
A database $\mathcal{D}$ of triples $(\sigma^1,\sigma^2,\mu)$, where $\mu$ is the distribution over $\{1,2\}$, indicating which segment the human preferred.
- If the human thinks 1 is better, then all the mass is on 1.
- If equal, then the distribution is uniform.
- If uncomparable, then it's not included in the database.
Why comparisons instead of scores? The authors found it much easier for humans to provide consistent comparisons than consistent absolute scores. On continuous control tasks, predicting comparisons worked much better than predicting scores — likely because reward scales vary substantially, complicating the regression problem. Comparisons smooth this out: you only need to predict which is better, not by how much. This mirrors the Elo system in chess — you don't need to know how "good" a player is on an absolute scale, just who beats whom.
#3 Preference Elicitation Flow
ManimWalkthrough of the 5-step preference collection process: segment sampling, pair presentation, human comparison, label recording, and reward model update.
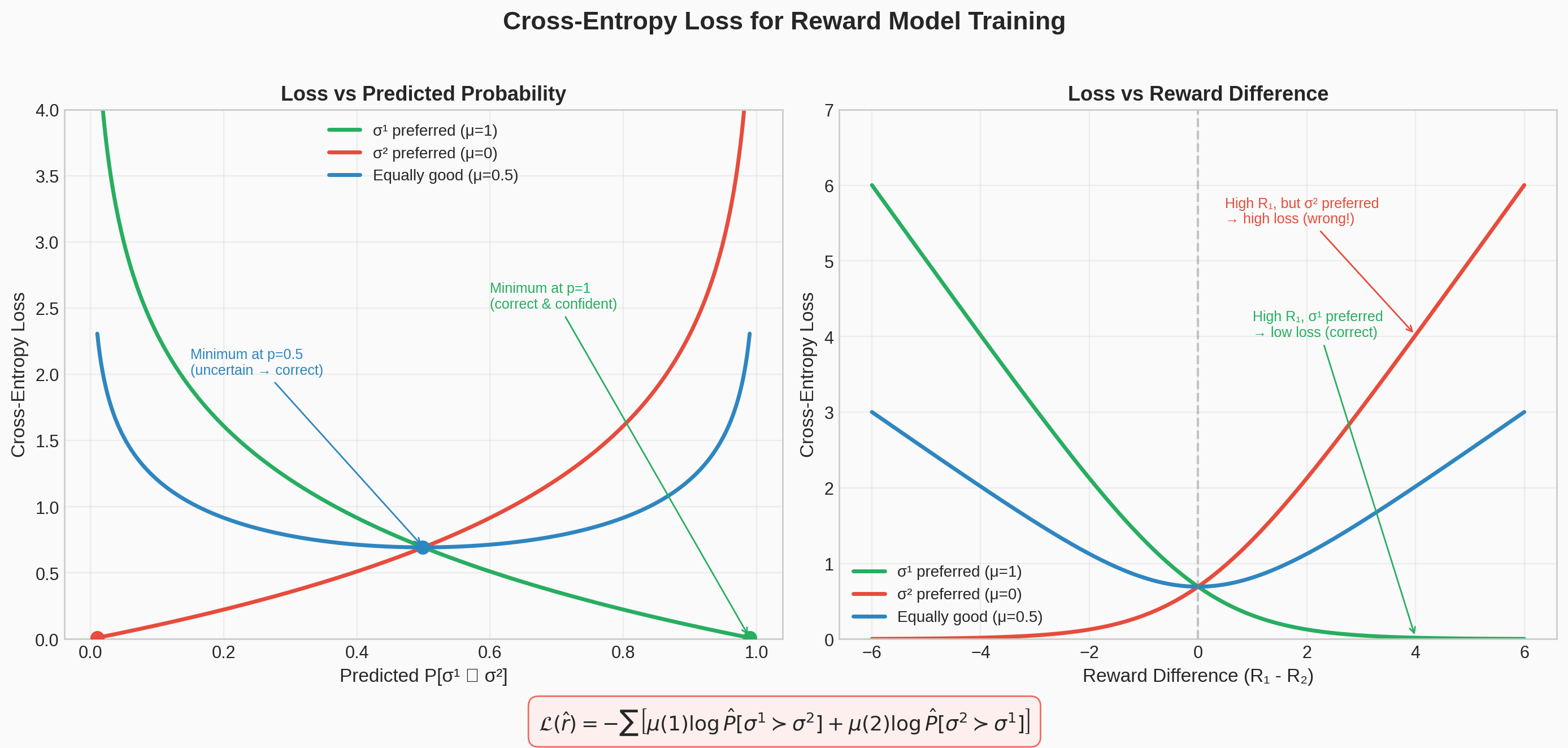
Fitting the Reward Function
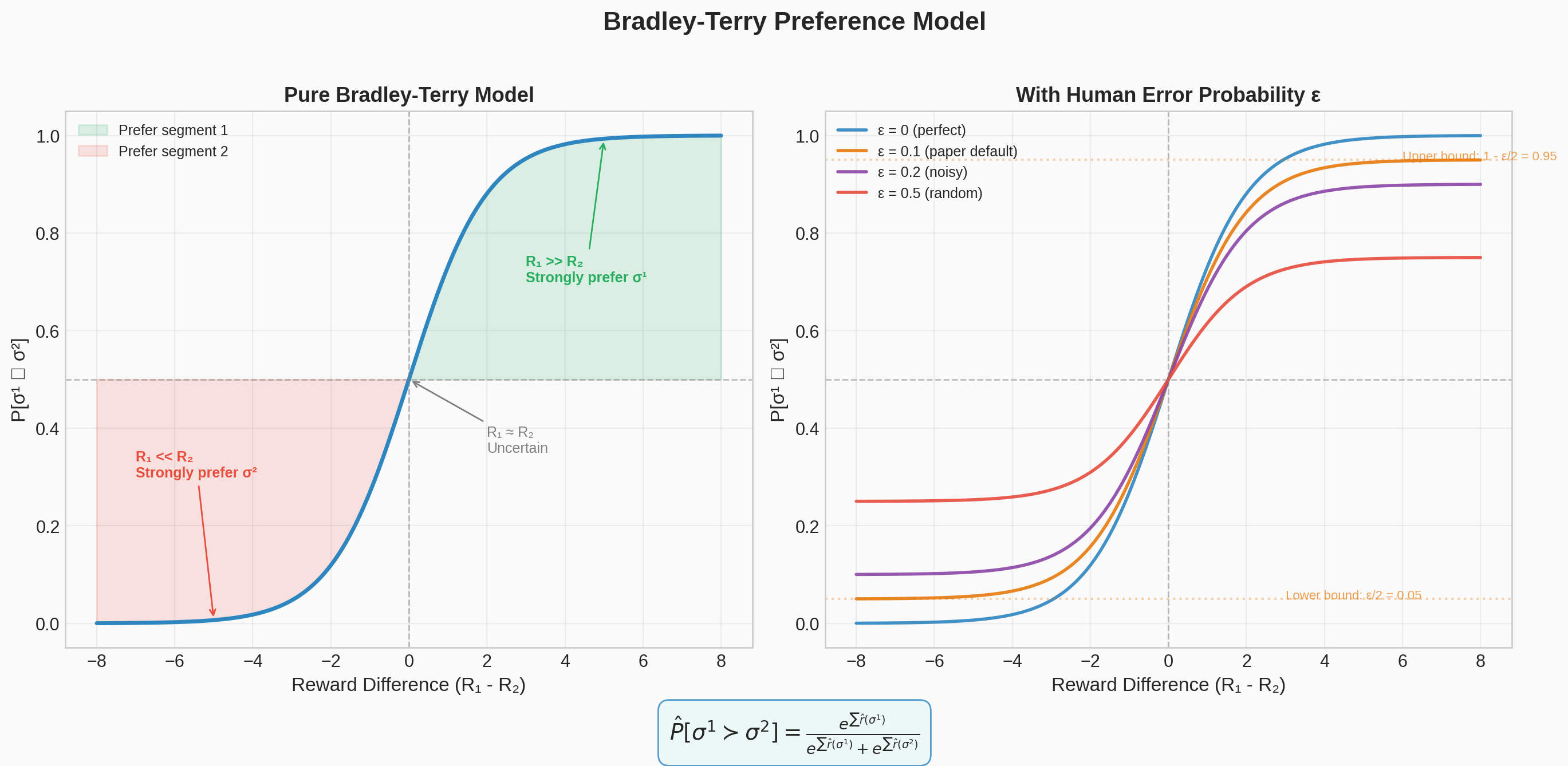
$\widehat{r}$ is interpreted as a preference-predictor, if we view it as a latent factor explaining the human's judgements and assume that the human's probability of preferring a segment $\sigma^i$ depends exponentially on the value of the latent reward summed over the length of the clip (here discounting isn't used):
This is basically converting the preference into probabilities and normalising it.
We choose $\widehat{r}$ to minimize the cross-entropy loss between these predictions and the actual human labels:
This follows from the Bradley-Terry model — estimate score functions from pairwise-preferences. It is also the specialization of the Luce-Shephard choice rule, to preferences over trajectory segments.
It's similar to how difference in Elo points for chess players is calculated pairwise, and estimates the probability of one player defeating another in the game — the difference in the predicted reward of two trajectory segments estimates the probability that one is chosen over the other by the human.
There were some modifications done in the approach:
- An ensemble of predictors were trained on $|\mathcal{D}|$ triples sampled from $\mathcal{D}$, with replacement. The estimate of $\widehat{r}$ is defined by independently normalizing each of the predictors and averaging the results.
- A fraction of $\frac{1}{e}$ is held out as a validation set for each predictor. L2 regularization is used, and val loss is between 1.1 to 1.5 times the training loss. In some domains, dropout was used too.
- Rather than using softmax directly, we assume that there is a 10% chance that the human responds uniformly at random. This is needed because human raters have a constant probability of making an error, which doesn't decay to 0 as the reward difference becomes extreme.
#4 Bradley-Terry Model
Matplotlib PlotlyThe Bradley-Terry sigmoid that converts reward differences into preference probabilities, with human error rate curves showing the effect of the epsilon parameter.
Static figure
Interactive demo — Open in new tab →
#5 Cross-Entropy Loss
Matplotlib PlotlyVisualization of the cross-entropy loss used to train the reward model on human preference comparisons, including a rotatable 3D loss surface and contour plot.
Static figure
Interactive demo — Open in new tab →
Selecting Queries
Preferences are queries based on an approximation to uncertainty in the reward function estimator.
- Sample a large number of pairs of trajectory segments of length $k$.
- Use each reward predictor in our ensemble to predict which segment will be preferred from each pair.
- Select those trajectories for which the predictions have the highest variance across the ensemble members.
This is a crude approximation — in some tasks it impairs performance. Ideally, we would want to query based on the expected value of the information of the query.
#6 Reward Convergence
ManimAnimation showing how the reward model's predictions improve and converge as more human comparison data is collected over time.
Experimental Results
In TensorFlow, MuJoCo and Arcade Learning Environment interfaced with OpenAI Gym.
RL Tasks with Unobserved Rewards
Solve a range of benchmark tasks for deep RL without observing the true rewards. The agent learns about the goal by asking a human which segment is better.
Feedback is given by contractors. Each trajectory segment is 1-2 seconds. Contractors responded in 3-5 seconds, total time was 0.5-5 hours.
For MuJoCo, 700 queries were sent to human raters. For Atari, 5,500 queries. A synthetic oracle (whose preferences exactly reflect the true reward) was also tested at 350, 700, and 1,400 labels for comparison. The baseline is standard RL with access to the true reward function.
You can use a synthetic oracle whose preferences over trajectories exactly reflect reward in the underlying task. Aim is to do well without access to reward information, and rely on the scarce feedback. Human feedback can do better however.
Variable-length episodes were removed to avoid encoding task information in the termination conditions — for example, ending the episode when the robot falls over implicitly tells the agent that falling is bad, even without a reward signal.
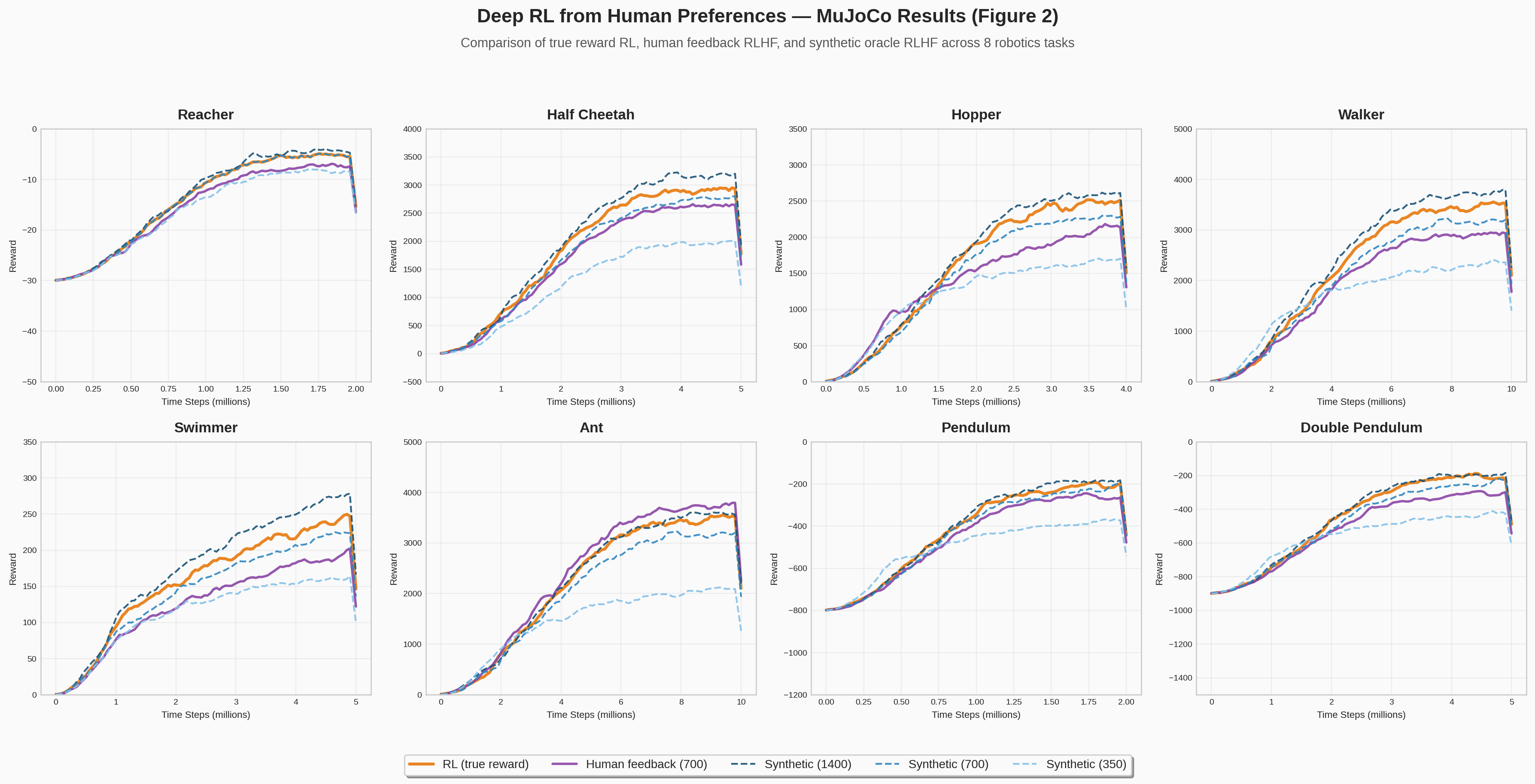
Simulated Robotics
Tasks: Hopper, Walker, HalfCheetah, Reacher, Ant, Swimmer, Pendulum, Double Pendulum — 8 tasks total.
Reward functions are linear functions of distances, positions and velocities, and all are quadratic functions of the features.
With 700 labels, the learned reward nearly matches standard RL on all tasks. At 1,400 labels, the RLHF agent actually slightly outperforms standard RL — likely because the learned reward is better shaped (it assigns positive rewards to all behaviors that are typically followed by high reward).
Real human feedback is only slightly less effective than synthetic. Depending on the task, human feedback ranged from half as efficient as ground truth to equally efficient.
On the Ant task, human feedback significantly outperformed synthetic because humans were asked to prefer trajectories where the robot was "standing upright," which provided useful reward shaping. The RL reward function had a similar bonus, but the simple hand-crafted version was not as useful.
#7 MuJoCo Results
Matplotlib8-panel reproduction of Figure 2 from the paper: learning curves across MuJoCo continuous control tasks comparing RLHF agents against RL baselines.
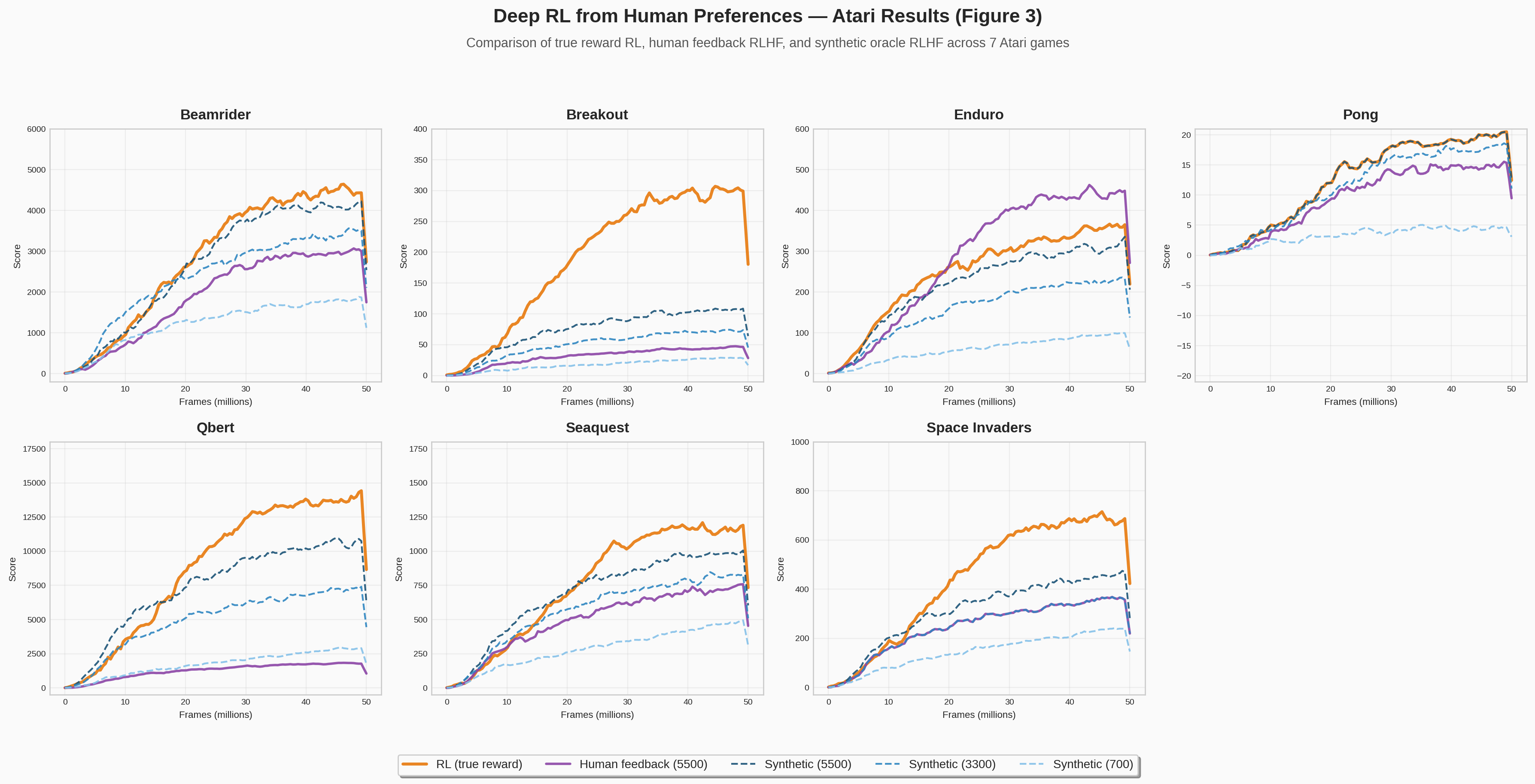
Atari
Games tested: BeamRider, Breakout, Enduro, Pong, Qbert, Seaquest, SpaceInvaders — the same 7 games from Mnih et al. (2013).
On most games, real human feedback is similar or slightly worse than synthetic, even if synthetic labels are 40% lesser. This may be due to human error in labelling, inconsistency between different contractors labelling the same run, or uneven rate of labelling by contractors. This can make some labels concentrated in the state space.
Specific results:
- BeamRider and Pong: synthetic labels match or approach RL with only 3,300 labels.
- Seaquest and Qbert: eventually reach RL-level performance but learn more slowly.
- SpaceInvaders and Breakout: never fully match RL, but substantial improvement — passing the first level in SpaceInvaders, reaching a score of 20-50 on Breakout.
- Qbert: fails with real human feedback — short clips are confusing and difficult to evaluate.
- Enduro: human feedback outperforms RL — humans reward any progress towards passing cars, essentially providing reward shaping that A2C can't discover through random exploration alone.
#8 Atari Results
Matplotlib7-panel reproduction of Figure 3 from the paper: learning curves across Atari games comparing RLHF agents against RL baselines.
Novel Behaviours
The ultimate purpose of human interaction is to solve tasks where no reward function is available. Using the same parameters as the benchmark experiments, the authors demonstrate:
- Hopper backflip: The robot learns to perform a sequence of backflips, landing upright each time, and repeat. Trained with 900 queries in less than an hour. This is a behavior you can recognize but would be very hard to specify as a mathematical reward function.
- HalfCheetah one-legged running: The robot moves forward while balancing on one leg. Trained with 800 queries in under an hour.
- Enduro driving with traffic: Rather than passing other cars, the agent learns to keep alongside them. Trained with ~1,300 queries over 4 million frames. The agent stays even with moving cars for a substantial fraction of the episode, though it gets confused by background changes.
These demonstrate the core promise of the approach: teaching behaviors you can recognize but can't easily demonstrate or specify as a reward function. A backflip is easy to judge ("did it land upright?") but nearly impossible to write as a mathematical function of joint angles and velocities.
Ablation Studies
Changes tested: random queries, no ensemble, no online queries (only those gathered at the beginning of training, not throughout), no regularization, no segments, target (true rewards).
In offline training, its performance was very poor. The nonstationarity of the occupancy distribution leads to the predictor capturing only a part of the true rewards, and maximising this partial reward can lead to bizarre behaviour that is undesirable as measured by the true reward. Thus, general human feedback is required.
For instance, on Pong, offline training sometimes leads the agent to avoid losing points but not to score points — resulting in extremely long volleys that repeat the same sequence of events ad infinitum. This demonstrates that human feedback needs to be intertwined with RL learning, not provided statically.
On the continuous control tasks, humans gave better scores/feedback. Prediction comparisons here was better than predicting scores. This is likely because the scale of rewards and scores makes things complicated.
There were large performance differences in using single frames rather than clips. Asking humans to compare longer clips was more helpful per clip and significantly less helpful per frame. Short clips took time to understand the situation for humans, but for longer ones, it was a linear function of the clip length. In Atari, easier to compare longer clips since there is more context.
The authors tried to choose the shortest clip length for which evaluation time was linear — rather than dominated by the human just trying to figure out what's happening in the scene.
#9 Ablation Heatmap
Matplotlib PlotlyHeatmap of the ablation study results showing the impact of different design decisions on final performance.
Static figure
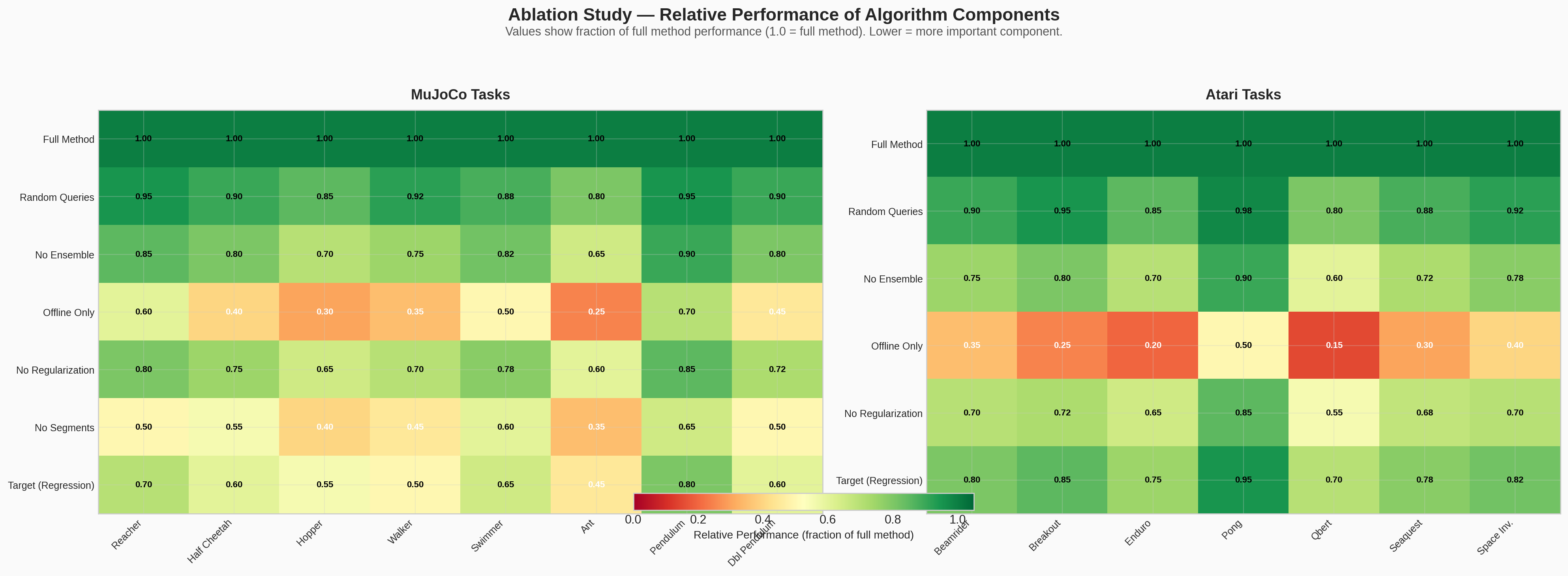
Interactive demo — Open in new tab →
Discussion and Conclusions
Agent-environment interactions are radically cheaper than human interaction. Learning a separate reward model using supervised learning reduces the interaction complexity by 3 orders of magnitude.
We can train deep RL agents from human preferences. Also, we are hitting diminishing returns on further improvements in non-expert feedback.
Compute vs. Human Cost
For the Atari experiments, compute cost was roughly $25 (a VM with 16 CPUs and one K80 GPU for about a day). Training with 5,000 labels corresponds to roughly 5 hours of human labor, totaling about $36 at US minimum wage. The fact that compute and human costs are already comparable means we're hitting diminishing returns on further sample-efficiency improvements.
Limitations
- The approach depends on the quality and consistency of human feedback. Contractors can be inconsistent, labels can cluster in narrow parts of state space, and some tasks (like Qbert) produce clips that are genuinely confusing to evaluate.
- The reward model can be exploited — the policy may find behaviors that score highly under the learned reward without actually being desirable. This is why online learning (continually gathering new feedback) is critical.
- The method is demonstrated on relatively simple environments. Scaling to more complex real-world tasks with higher-dimensional observations remains an open challenge.
Historical Significance
This paper, authored by researchers from OpenAI (Christiano, Brown, Amodei) and DeepMind (Leike, Martic, Legg), established the RLHF framework that would reshape AI development. The same approach was later scaled to language models in Learning to Summarize from Human Feedback (Stiennon et al., 2020), then to InstructGPT (Ouyang et al., 2022), which directly led to ChatGPT. Dario Amodei went on to co-found Anthropic, where RLHF remains central to Claude's training. Jan Leike later led alignment research at OpenAI. This paper is where that entire trajectory began.
Implementation: Cat Grid-World RLHF
We implemented the paper's RLHF framework on a minimal 8×8 grid world: a cat at (0,0) must reach the goal at (7,7), avoiding a trap at (1,0) and a wall at (1,1). A synthetic oracle provides preference comparisons using distance-shaped rewards, and the agent learns both a reward model and policy from these preferences alone — exactly as described in the paper.
All visualizations below render from a single training run (100 iterations, ~40s on CPU). Data is loaded from rlhf_results.json and rendered client-side with Canvas and Plotly.
Loading demo data...
Learned vs Optimal Policy
Arrows show the best action at each cell. Learned policy arrows are blue with opacity proportional to confidence. Red-highlighted cells show disagreements with the optimal policy.
Learned Reward Heatmap
Cell color shows the reward model's best-action prediction. Green = positive (good), red = negative (bad), dark = near zero. Small arrows indicate the reward model's preferred direction. Compare with the optimal policy to see where the reward model has captured the right incentives.
Training Curves
Policy performance and training metrics over 100 RLHF iterations. Policy accuracy is evaluated against the DP optimal baseline every 5 iterations.
Trajectory Animation
Watch the trained policy navigate the grid. The orange marker shows the cat's current position; fading trail shows past steps with step numbers every 5th step.
Preference Pair Replay
Browse segment pairs from the preference database. Each pair shows two trajectory segments (numbered steps on the grid) that the synthetic oracle compared — analogous to the 1-2 second video clips shown to human raters in the paper.
#10 Interactive Preference Simulation
PlotlyFull interactive RLHF preference simulation: generate trajectory pairs, make preference comparisons, and watch the reward model learn in real time.
Interactive demo — Open in new tab →